Welcome to part 2 of Benchmarking Data-Oriented Design.
In part 11 we benchmarked data-oriented design by comparing a struct of arrays vs an array of structs. Both of these data structures used value types as array elements. Today we will compare how the type of array elements affect performance - value types vs reference types.
First, a short intro to value types and reference types and how they relate to our data-oriented design benchmark.
Value types #
Value types, such as booleans, bytes, integers, floats, or structs, are stored in one or more contiguous bytes of memory. Arrays of value types are stored as one big contiguous section of memory like so:
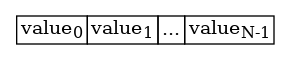
When we iterate over an array of value types we are effectively reading a single contiguous section of memory sequentially, which means we utilize the CPU cache efficiently in a couple of ways.
- Cache prefetching. The CPU cache prefetcher typically recognizes when we are reading memory sequentially and predicts what section of memory we will read next. It then prefetches the following memory sections into cache before we need it. This means we get cache hits which is good.
- Cache line utilization. If values are small and multiple values fit into a single cache line, then we get even more cache hits.
Reference types #
Reference types contain a reference to one or more values which are located in different memory locations, separate from the reference. An array of reference types stores all references in a contiguous section of memory, but the values are scattered around at different places in memory like so:
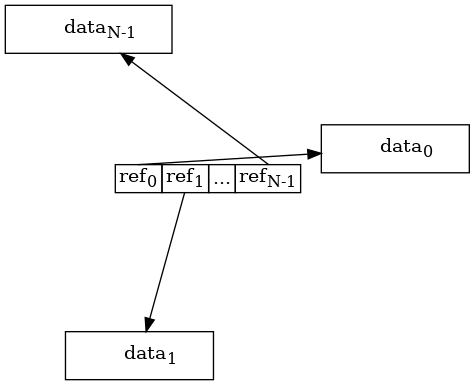
The reference types introduce a level of indirection: first we read the reference, then we load the data section from the referenced memory address. This usually leads to random memory access patterns, which is bad for CPU cache performance. When we iterate over an array of reference types we get the CPU cache benefits only for the references. Typically, we get a cache miss each time we read a data section.2
Benchmark #
Let's expand the benchmark from part 1: iterating over 1 million users and finding out which email addresses are still unconfirmed. Today we'll use pointers, a simple form of reference type, and benchmark arrays of pointers against the arrays of value types from part 1.
1// userRefs is an array of references
2var userRefs []*user
3
4type user struct {
5 ID int
6 IsActive bool
7 Name string
8 Username string
9 PasswordHash []byte
10 MustChangePassword bool
11 Email string
12 EmailConfirmed bool
13}
14
15// users is a struct with arrays of references
16var users userRefData
17
18type userRefData struct {
19 ID []*int
20 IsActive []*bool
21 Name []*string
22 Username []*string
23 PasswordHash []*[]byte
24 MustChangePassword []*bool
25 Email []*string
26 EmailConfirmed []*bool
27}
Running the benchmark3, we get the following results:
Iterations Time Memory throughput Data processed
BenchmarkValueTypes/array-of-structs-4 121 9906752 ns/op 10497.89 MB/s 99.18 MB/op
BenchmarkValueTypes/struct-of-arrays-4 588 1974807 ns/op 586.80 MB/s 1.105 MB/op
BenchmarkRefTypes/array-of-references-4 127 9240654 ns/op 12120.35 MB/s 106.8 MB/op
BenchmarkRefTypes/struct-of-ref-arrays-4 123 9478477 ns/op 974.58 MB/s 8.810 MB/op
The BenchmarkValueTypes lines benchmark value types and the BenchmarkRefTypes lines benchmark the reference types.
Both reference type benchmarks perform quite close to the BenchmarkValueTypes/array-of-structs benchmark in terms of time per operation.
This shows that reducing the size of the reference type array element, from struct to single values, didn't improve performance.
An interesting detail is that BenchmarkRefTypes/struct-of-ref-arrays reads an order of magnitude less data per operation than BenchmarkRefTypes/array-of-references (8.8 MB/s vs 106.8 MB/s) but they both perform similarly in terms of time per operation.
This indicates that the random memory access patterns that reference types introduce prevent the CPU cache from being efficiently used.
As in part 1, BenchmarkValueTypes/struct-of-arrays shows that if we use an array of value types with small sized elements, we can utilize the performance boost that the CPU cache gives.
The struct-of-arrays (value type) performs 5x faster than the others.
Summary #
In order to be able to benefit from data-oriented design, it is important to understand the difference between value types and reference types and what their memory layout looks like. It is also important to understand the effect of random memory access patterns that reference types introduce, and their effect on CPU cache utilization.
CPU cache utilization is not an precise form of engineering, but we can get a good idea on how different data structures and algorithms perform by using benchmarks. These benchmarks helps us get a better understanding and intuition for how the CPU cache works.
-
It might be possible to get a good cache hit ratio for an array of reference types if we have allocated the referenced data sections in a contiguous section of memory, and are iterating over it in a predictable pattern. For example, if the data sections were stored as an array of value types. ↩︎